Nowadays, most image feature extractors are trained in classification tasks where little or no clinically relevant metrics are implemented in the loss function.
Our goal is to find ways to extract better medical image features through tasks that allow extractors to preserve important information.
Why?
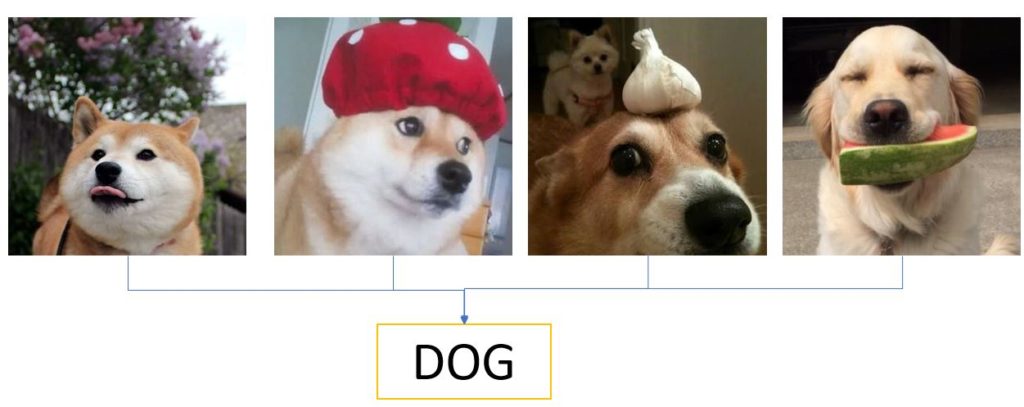
Figure 1.
Classifiers are incomplete
Clinical judgement over medical images require professionals to understand subtle differences between similarly looking objects.
A traditional classifier would learn that all the images from the top panel of Figure 1 represent dogs. Yet as the bottom panel shows, there is a lot of information available that would be ignored
Medical images are complex
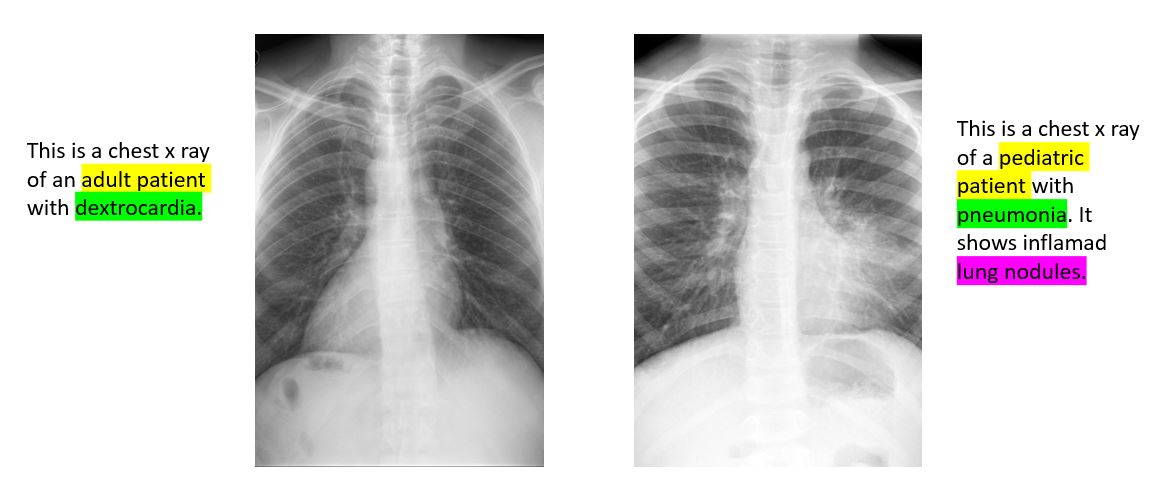
If we want computers to understand images as doctors do (Figure 2), algorithms must implement richer feature extractors aimed towards human level abstraction of medical pictures. These may require tasks beyond classification to be trained. We propose to train extractors through natural language and multimodal architectures.
Figure 2.
Project Development Areas
Medical Image captioning
We are training state of the art captioning models with medical images and evaluating the usefulness of the extracted representations to identify relevant medical information such as imaging modality, anatomy and findings.
Multimodal encoders
We are developing hybrid architectures to take on different images aswell as clinically relevant information to generate useful image features.
Contrastive learning
We are exploring alternative loss functions such as those prioritizing contrastive learning to allow for better differentiation of medical concepts.